联合共建:深圳市健康城市研究和数据分析中心、纳尼(深圳)咨询有限公司
电话:+86 13538048576地址:深圳市龙岗区龙城街道紫薇社区吉祥中路234号碧湖玫瑰园10栋303


2021年7月,深圳市健康城市研究与数据分析中心客座高级研究员李悦博士(哈佛大学陈曾熙公共卫生学院环境健康系)与合作者在《PLOS ONE》期刊发表题为《基于日常电话会话中声学特征的痴呆风险识别:一种新型机器学习预测模型》的研究论文。该研究首次证实:通过分析老年人日常与人工智能系统的电话交谈录音,即可高精度识别阿尔茨海默病风险,为突破痴呆症早期筛查的成本与技术瓶颈提供了可大规模部署的社区解决方案。
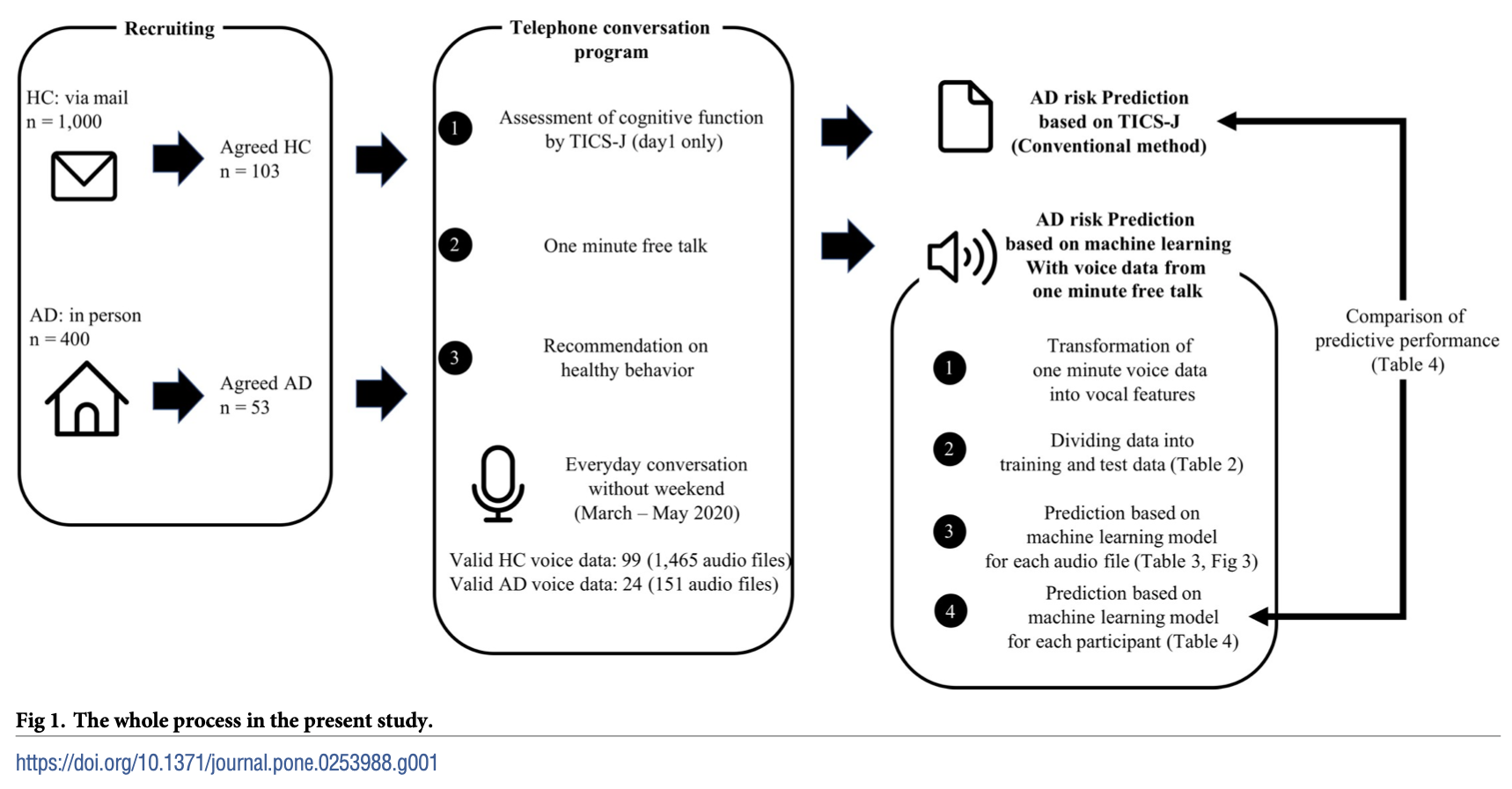
我中心成员李悦博士与京都大学团队利用日本八王子市2020年3月至5月实施的痴呆症预防项目中获取的1616份音频文件(来自99名健康对照者、24名轻中度阿尔茨海默病患者),通过PRAAT语音分析软件提取了60项声学特征,涵盖音高、强度、语速、停顿时长、频谱重心等维度。研究团队创新性地采用极端梯度提升(XGBoost)、随机森林(RF)及逻辑回归(LR)三种机器学习算法构建预测模型,并与国际通用的日本版电话认知状态访谈量表(TICS-J)进行头对头比较。
研究结果展现出卓越的临床转化潜力:基于单次音频文件的预测模型中,三种算法的曲线下面积(AUC)均达到0.86-0.89;而当以每位参与者全部音频文件的预测均值作为判断依据时,XGBoost与随机森林模型的AUC高达1.000,优于TICS-J量表的0.917,且XGBoost与量表评分的准确性差异已接近统计学显著性(p=0.065)。这意味着,仅通过分析老年人两周内每日1分钟的自由叙述录音,即可实现近乎完美的痴呆风险分层。
从公共卫生政策视角,本研究具有三重突破性价值:其一,验证了“被动式、非侵入性、零负担”的群体筛查可行性。传统认知筛查依赖专业人员面对面施测或结构化量表电话访谈,人均耗时15-30分钟;而本方案利用既有社区服务热线、政务客服等场景中的日常通话数据,无需额外检查设备与受试者主动配合。其二,首次系统揭示了与阿尔茨海默病病理进程高度关联的声学生物标记物谱系,包括最长无声时长增加、音高变异性下降、频谱重心偏移等,为开发病理机制驱动的数字标志物提供了实证基础。其三,提供了可即时部署的算法模型与特征工程开源框架,研究使用的PRAAT脚本与Python特征提取代码已在论文补充材料中完整公开,任何地区卫生部门仅需配置常规服务器即可复现该系统。
研究团队在讨论部分特别指出,该模型在健康对照者与已确诊患者间的极端区分能力(AUC=1.000)需在更大规模的前瞻性队列中谨慎验证,当前结果可能受限于样本量及病例对照设计。然而,模型对轻中度患者及主观认知下降人群的灵敏度分析(见附表S2)显示,即使在病程早期,声学特征的变化已具有可检测的统计学信号。基于此,李悦博士团队已联合深圳市健康城市研究与数据分析中心启动“鹏城之声——社区老年语音认知风险评估”验证项目,计划在深圳市3个行政区招募2000名65岁以上老年人,开展为期2年的前瞻性队列观察,旨在建立中国人群语音认知衰退轨迹模型及跨文化适用的声学生物标记物参考阈值。
本研究标志着人工智能语音分析从“实验室概念验证”迈向“社区公共卫生工具”的关键一步。目前,研究团队已形成面向基层医疗卫生机构的定制化服务能力,可为区县级疾控中心、社区健康服务中心及养老服务机构提供:智能语音认知风险筛查系统本地化部署、现有政务服务热线语音数据匿名化分析、认知障碍友好社区干预效果语音评估工具开发等技术支持。我们期待与各地卫生健康部门、老年社会服务机构及数字医疗企业合作,共同推进低成本、可及性强的认知障碍早筛技术惠及更广泛人群。
如您对本研究的算法模型、社区验证方案或定制化部署服务感兴趣,欢迎与我们联系:contact@shcrdc.org。
论文信息:
Dementia risks identified by vocal features via telephone conversations: A novel machine learning prediction model. Yue Li et al. PLOS ONE, 2021 Jul 14;16(7):e0253988.
DOI: 10.1371/journal.pone.0253988 │ PMCID: PMC8279312
原文链接:https://pmc.ncbi.nlm.nih.gov/articles/PMC8279312/

联合共建:深圳市健康城市研究和数据分析中心、纳尼(深圳)咨询有限公司
电话:+86 13538048576地址:深圳市龙岗区龙城街道紫薇社区吉祥中路234号碧湖玫瑰园10栋303






